




































RFID Encodings: Input Characters to Bits and Back to Characters

With the continued expansion of RFID tagging, many users are shifting from the question of which numbering system to encode on the tags to how to actually get the numbering system’s characters encoded to the tags. For the primary question, we have standards such as GS1’s Tag Data Standard 2.0 or ISO’s 1736x -Series to guide users in the right direction. The latter question is a bit more complex and is dependent on several criteria. Our RFID Subject Matter Expert, Chris Brown, sheds some light on the topic below.
A Chain of Data
Determining which characters to encode your RFID tags is often confusing. It’s even more confusing for people when the data (characters) that they subsequently read are different than what they encoded. To understand this topic, think about a chain of data that starts with the characters that you are trying to encode, then in the middle, we have the memory on the chip where those characters are to be stored, and at the end of the chain, we have the reader that reads the tag chip and displays the characters.
Determine the Character Set
Let’s start in the middle, your tag chip. The memory on tag chips is just a series of bits. The value of each bit can only be a 0 or a 1. If I am only trying to encode 0’s and 1’s (and read the data later as a series of 0’s and 1’s), then this is all quite simple.
For example, if I want to encode 0101, then that is what I would flip the bits in my tag chip to. That is what I would read with my reader, and that is what I would display in my application. This is a simple solution.
However, your average user does not want to think in bits. Instead, most people work with characters like “A” and “7” or even “!”. At the beginning of the chain, we have what I call your input character set. Others might call this your code page or just character set. Your input character set is determined by several criteria.
For example:
- What characters will be encoded? Numeric characters like 1234? Or do you also need alphabetic characters in there like XYZ? Can I limit my input character set to Hexadecimal characters (0-9 and A-F)? What about capital and lowercase letters? What about international characters like the Spanish “Ñ” or Germanic “ü”? Maybe Asian kanji characters (yes, some Japanese automotive manufacturers want to encode kanji characters)?
- Are you required to encode as per a spec, and does that spec require a specific input character set?
Some example input character sets are (listed from simple to more complex):
- Decimal values (numbers based on the characters 0-9)
- Hexadecimal (0-9 and A-F)
- ISO/IEC’s limited alphanumeric character set intended for 6-bit encoding
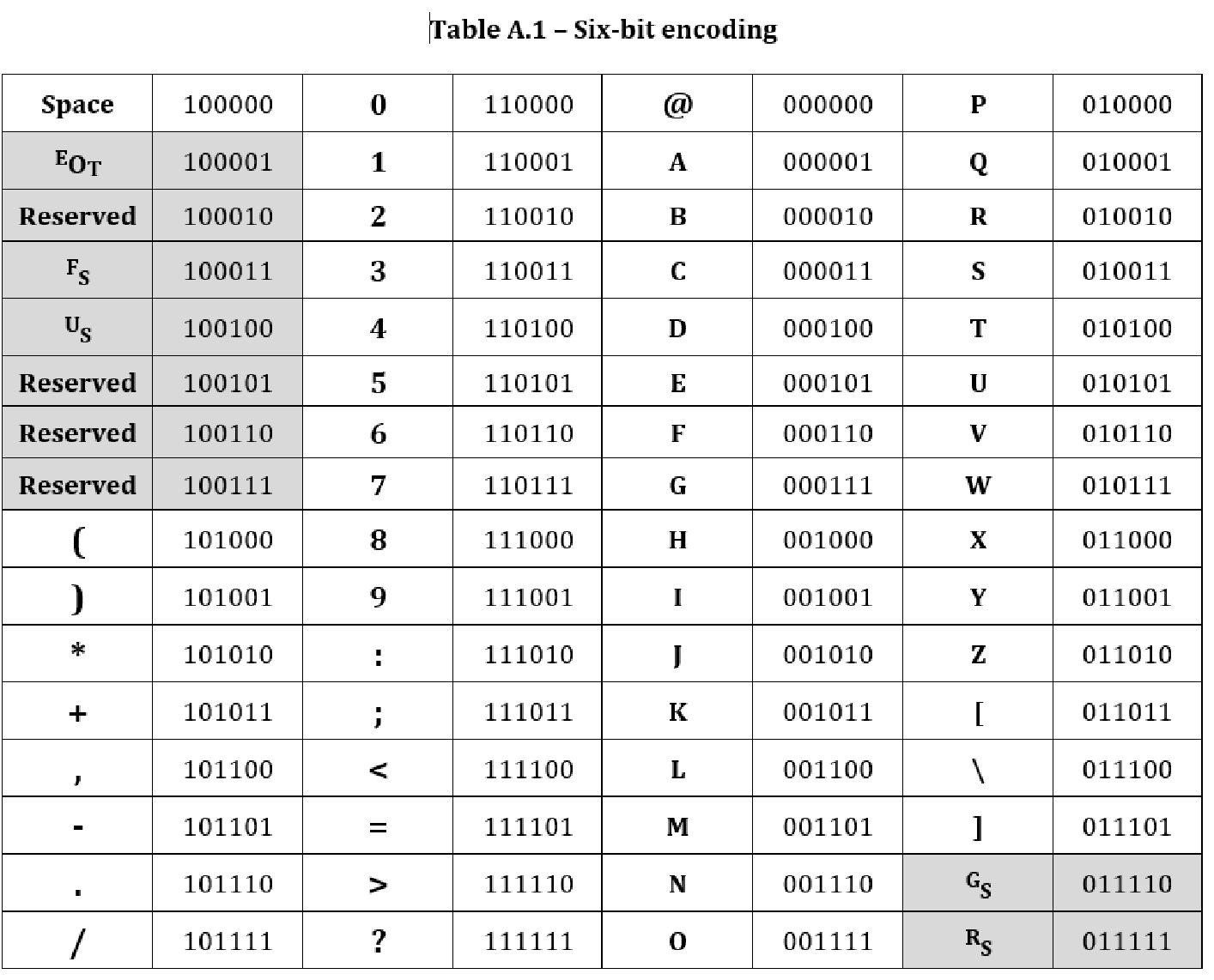
- 7-bit ASCII
- Extended ASCII (8-bit)
- Kanji
- All the way up to multi-byte Unicode – maybe I want to encode some Arabic, Japanese and Cyrillic characters on the same tag (this is an extreme example, but RFID standards should consider such extremes)
Determine the Encoding
Once you have determined the character set you need to use for your input values, you now need to determine what most RFID experts would call the “encoding.” This is not the best term for this, because this term gets used for many other meanings – including in this article - but we will stick with encoding. In this context, encoding is defined as how many bits and in which combinations are used to represent each input character.
For example, if my input character set is Hexadecimal, then I would normally use the conventional Hexadecimal-value-to-bit encoding shown here (keep in mind that these conversions are ultimately just convention):
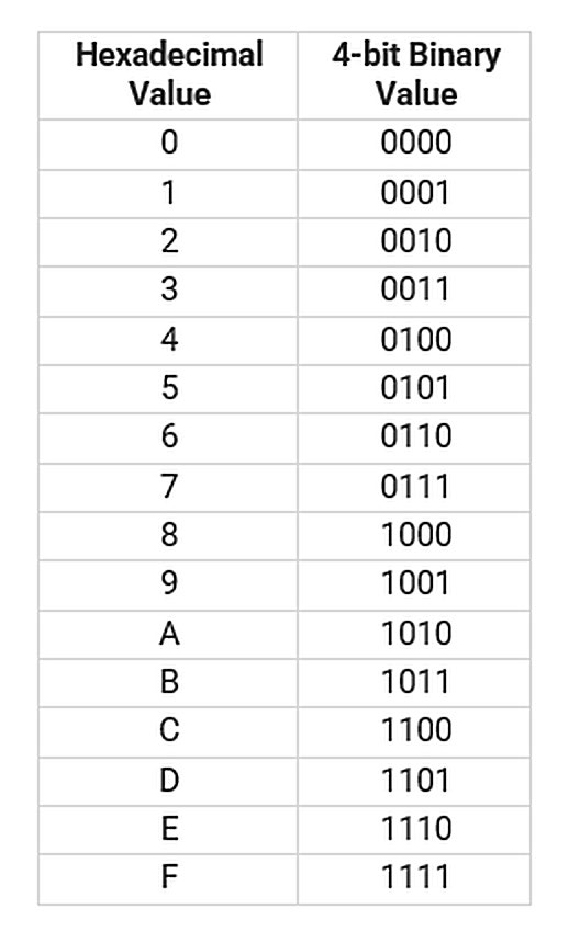
To continue the Hexadecimal example, let’s say you want to encode the value of “FA25” (my input characters for a specific tag). Your encoding device would receive this value from some input application and flip the bits on the chip to “1111 1010 0010 0101” (I added the spaces for clarity’s sake; they would not be part of this encoding). People would call this a 4-bit encoding, meaning that it takes 4 bits to encode each character.
Getting a little more complicated, you might need to encode even more alphanumeric input characters than are found in Hexadecimal If you only need basic alphanumeric characters found in ISO’s simplified alphanumeric character set shown above, then you could use this character set (code page) and would need 6 bits per character, also as shown in the same chart.
Please note that this particular ISO character set does not distinguish between lower and upper-case alphabetic characters. If you wanted to encode both lower and upper-case alphabetic characters, then you would need a character set that covered both and will consequently need more bits per character. There are several 7-bit encodings that support alphabetic upper and lower-case characters, but it is more common to use an 8-bit per character encoding and call it a day. You consume an extra 1-bit for each character you encode, but chunks of 8 bits are easier for encoding devices and readers to work with, so it is generally deemed better to go with 8 bits per character.
Determine the Reader’s Configuration
Now we jump to the end of the chain, the reader. Your reader is ultimately reading just 0’s and 1’s from the chip. This means that if you wish to retrieve the same characters that you originally input, then your reader or another application needs to be configured to convert the bits into the desired characters based on both the input character set and encoding in use. Many readers are configured to convert the data to Hexadecimal by default, and this can lead to confusion, so be on the lookout for this.
Another thing to consider is the question of which input character set and which encoding (the conversion of characters to bits) to select. If you are encoding tags according to a standard, then the answers are normally part of the standard. You don’t get a choice.
If you are encoding tags for your own closed-loop application, then make sure to select an input character set that covers all of the characters you will need and select an efficient encoding – efficient in this case usually means using as few bits per character as possible. Using fewer bits means you need less memory on your tags which consequently allows for the use of cheaper tags. Additionally, the tags can be read more efficiently and with fewer errors as there are fewer bits flying back and forth across the air.
Lastly, different portions of tag memory can be encoded based on different input character sets and using different encodings. For example, you might have an alphanumeric serial number using an 8-bit encoding followed by a numeric date using a 4-bit encoding. Again, if you are encoding as per a standard, then this will be covered, but if you are encoding tags for your own closed-loop application you can do as you wish.
One final note: If you are encoding tags for your own closed-loop application, it is strongly recommended to use the new RAIN Alliance ISO-based numbering system as a “wrapper” around your proprietary data to avoid tag clutter.
Your Barcode and RFID Label Printing Experts
We are committed to keeping you in the know on all things RFID labeling. For implementing RFID labeling solutions in your enterprise check out our website or contact us here.


